Finetune Large Models
Nowadays, it is common practice to develop new machine learning projects starting from a large pre-trained model and fine-tuning it to the task at hand. Sam Altman, at the time of writing the CEO of OpenAI, recently mentioned that he envisions a feature where the most valuable startups are the ones capable of adapting publicly available foundation models to specific domains; rather than training a proprietary model from scratch. Thus, tuning or fine-tuning large models is a key capability that machine learning practitioners need to learn as much as being able to train a deep neural network was a major skill that each scientist had perfected in the last few years.
On the web, there are a plethora of recipes for training neural networks (thanks Karpathy you saved me multiple times). Instead, there are only limited amount of resources tackling the fine-tuning problem. To this end, this article aims at describing the strategy that I adopt when fine-tuning a large Transformer model.
The Procedure
The procedure here-described is built on the key principle that: the fine-tuning step should be the continuation of the training phase but on a different dataset. The main focus is on avoiding the introduction of any unnecessary difference between the original and fine-tuning tasks at every stage of the pipeline. Therefore we will minimise the number of parameters that need to be adapted: resulting in greater transferability between tasks.
1. Dataset Preprocessing
Often catastrophic forgettin is caused by a bad implementation of the preprocessing steps applied to the fine-tuning dataset.
On the one hand, for natural language processing tasks additional cares need to be taken during the tokenization of the input text. Specifically, always double-check that the correct tokenizer is applied, and that the correct PAD-token is adopted. HuggingFace made a terrific effort in providing a bug-free implementation of most Transformers models, but sub-word tokenizers remain a challenging module to operate. Another error-prone transformation is the creation of the input mask: always assert that causal and padding masks are correctly combined and applied in the correct layer.
On the other hand, in computing vision tasks, ensure that the proper transformations are applied to the input images. Order of the input channel, and normalization and interpolation strategy for the resizing steps are among the most error-prone functionality to correctly re-create.
Finally, if you are working with graph structures, double-check how you uniformize to a fixed size a batch of nodes having a different amount of neighbours.
2. Optimizer
According to the key principle of this article, the fine-tuning procedure should use the same optimizer adopted during training. While this is not always possible, most of the foundation models [1] are trained by applying the AdamW optimize [2]. AdamW is a variation of the well-known Adam algorithm that better generalize to unknown examples thanks to the decoupling of the main loss and the regularization term known as weight decay. Note that back in the day, PyTorch did not provide a proper implementation of the AdamW. Thus, multiple open-source projects provided their implementation. Across the many, the one provided by Meta’s fairseq is highly reliable and I still use it nowadays.
3. Weight Decay
By default, AdamW will apply the weight decay mechanism to all models’ parameters, yet in most cases, weight decay is NOT applied to all weights. The weight decay objective is to regularise the training process toward learning models with weights smaller in magnitude. To this end, biases and gains are usually not included in the weight decay loss for multiple reasons:
- Biases are used to shift the activation function of a neuron and do not typically have a significant impact on the overall complexity of the model. As a result, applying weight decay to the biases would not have a significant effect on the model’s ability to overfit.
- Gains are commonly used in normalization layers to enable high expressivity while ensuring gaussian-like activations. Thus, biases do not typically have a significant impact on the model complexity. On the contrary, weight decay applied to gains might limit the expressivity of a model resulting in underfitting.
- Overall, weight decay is typically applied only to the weights of a model, rather than the biases or gains, to encourage the model to use small weights and reduce the risk of overfitting. In PyTorch this is commonly achieved by creating two groups of parameters for the optimizers.
def get_group_params(
model: nn.Module,
weight_decay: float = 0.01,
no_decay_patterns: Optional[List[str]] = ["bias", "ln_.+weight", "ln_.+bias"],
) -> list[dict[str, Any]]:
"""function generating the appropriate group's parameters to optimize
:param model: model to train
:type model: nn.Module
:param weight_decay: weight decay factor, defaults to 0.01
:type weight_decay: float
:param no_decay_patterns: regex patterns used to identify parameters for witch no decay is used, defaults to ["bias", "ln_.+weight", "ln_.+bias"]
:type no_decay_patterns: Optional[List[str]], optional
:return: two groups of parameters to optimize
:rtype: list[dict[str, Any]]
"""
optimizer_grouped_parameters = [
dict(
params=[
# parameters with weight decay
p for n, p in model.named_parameters() if not any(
[re.search(pattern, n) for pattern in no_decay_patterns]
)
],
weight_decay=weight_decay,
),
dict(
params=[
# parameters without weight decay
p for n, p in model.named_parameters() if any(
[re.search(pattern, n) for pattern in no_decay_patterns]
)
],
weight_decay=0.,
)
]
return optimizer_grouped_parametersIf you don’t like regex patterns, karpathy provided a nite alternative implementation in its miniGPT repository.
4. Learning Rate
While finetuning your models, you will be surprised but you will find out that the best-performing learning rate will be quite small. A sound starting point is a learning rate of 5e-5. As overmentioned, such a learning rate is extremely small compared to when you train a neural network from scratch, but it will fit the new data well and prevent catastrophic forgetting.
Moreover, in many cases, it is beneficial to use a learning rate scheduler while fine-tuning your model. Across the many schedulers a linear decay scheduler with a warmup phase works well while being simple to implement.
from torch.optim.lr_scheduler import LambdaLR
from torch.optim.optimizer import Optimizer
def get_linear_scheduler_with_warmup(
optim: Optimizer,
num_warmup_step: float,
num_training_step: int,
last_epoch: int = -1,
):
"""
get a scheduler that linearly increase the learning data between [0, num_warmup_steps) and then linearly decrease
it between [num_warmup_steps, num_training_step).
"""
def lr_lambda(current_step):
if current_step < num_warmup_step:
return float(current_step) / float(max(1.0, num_warmup_step))
return max(
0.0,
float(num_training_step - current_step) /
float(max(1.0, num_training_step - num_warmup_step)),
)
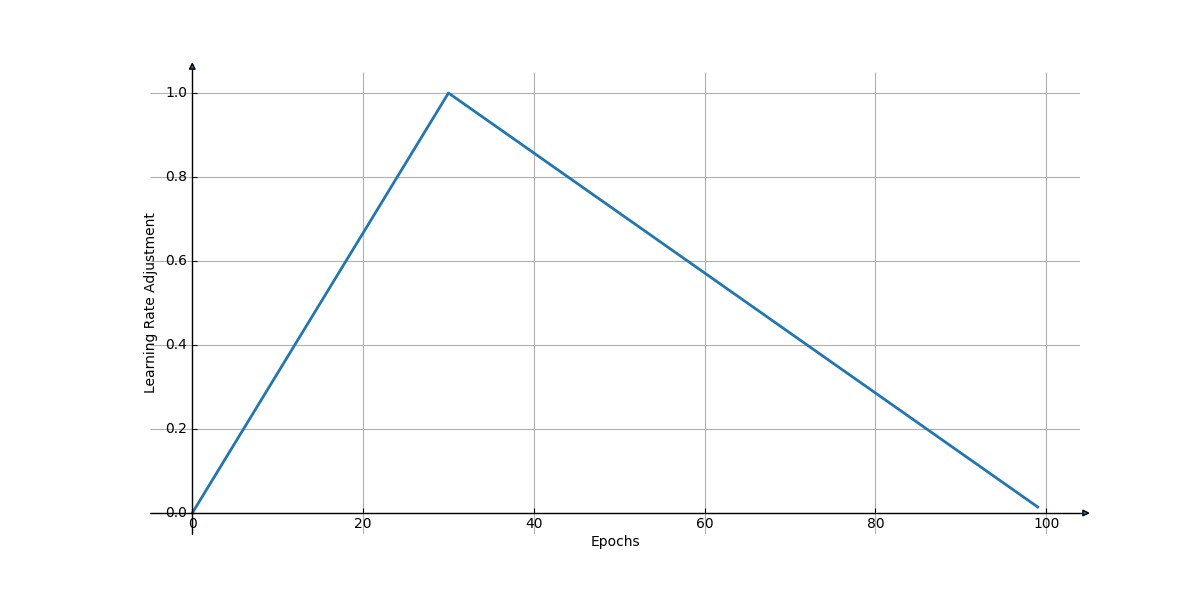
return LambdaLR(optim, lr_lambda, last_epoch)The assumption is to linearly increase the learning rate during the warmup phase (usually lasting for one epoch) to align the model’s parameters to the new task. Afterwards, the learning rate is reduced to allow for fine-grained adjustments of the weights. Figure 2 shows how the learning rate is adjusted across different epochs.
Note that adopting a learning rate scheduler is beneficial, but it introduces many challenges for reproducibility. Schedulers adapt the learning rate according to the epoch and the dataset size. Thus, by simply modifiing the dataset you will likely change your scheduler. Be carefull !!!
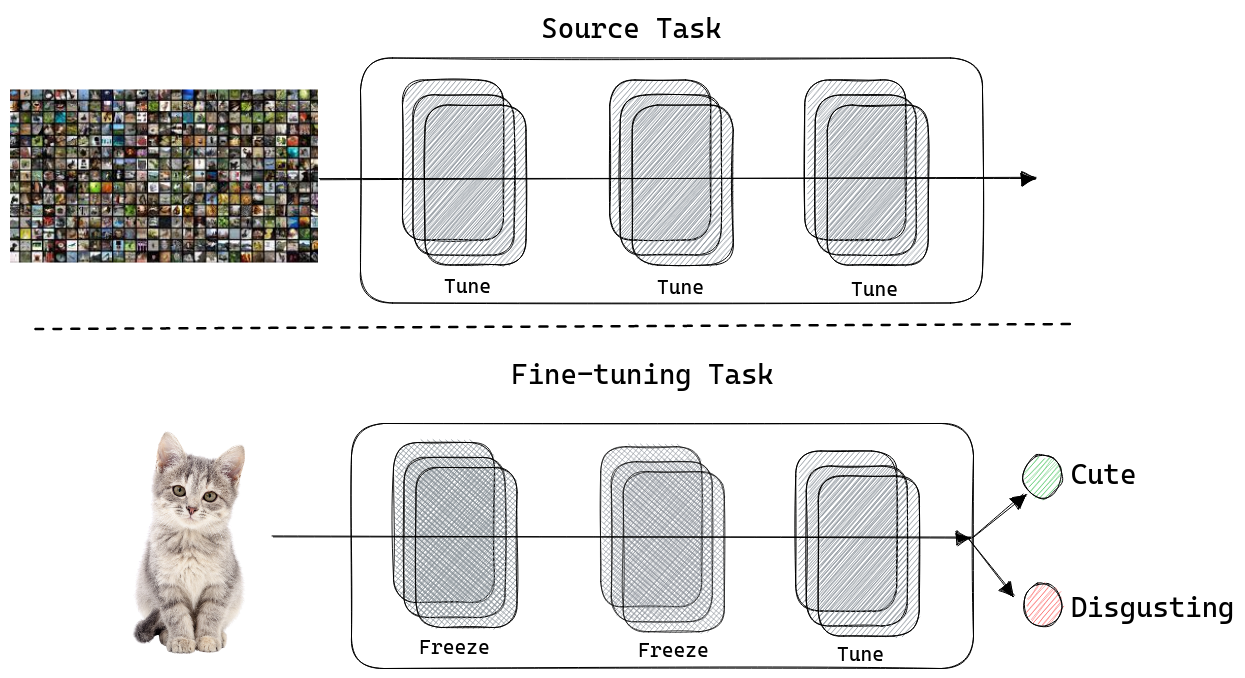
5. Parameter feezing
To achieve good transferability and avoiding chatastorfic forgetting it is key to implement a proper parameter freezing stragegy. As over-mentioned it is important to minimise the number of parameter to ajdust during the fine-tuining phase to guarantee transferability across tasks. To this end, [3] proposed to only adjust bias terms to achieve a good tradeoff between learning speed and transferabilty performance. Similarly, in a multilingual setting it is common to keep frozen the embedding layers as well as the first few layers of a multilingual-BERT models ([4]) demonstrated that the first 8 layers need to be keep frozen, while the remaining are tasks-specific). Finally, the same effect is also observable in computer vision assignment: in [5] it is reported how freezing the lowest layers is key to obtain good generalization.
Freezing parameters is extramly easy in PyTorch thanks to the requires_grad flag associated to each model’s parameter:
def unfreeze_layer_params(
model: nn.Module,
freeze_patterns: list[str] = [".*bias$"],
):
for n, p in model.named_parameters():
if any([re.search(pattern, n) for pattern in freeze_patterns]):
# unfreeze biases parameter
p.requires_grad = True
print(f"unfreeze -> {n}")
else:
# freeze remaining parameters
p.requires_grad = False
print(f"FREEZE -> {n}")6. Overfit
Finally, it is recommended to evaluate the training scripts on a single batch before executing the fine-tuning procedure. The benefits of this exercise are twofold:
- it enables us to detect errors or hardware limitations in the fine-tuning procedure at a low cost;
- it ensures that our model will be able to fit the fine-tuning dataset.
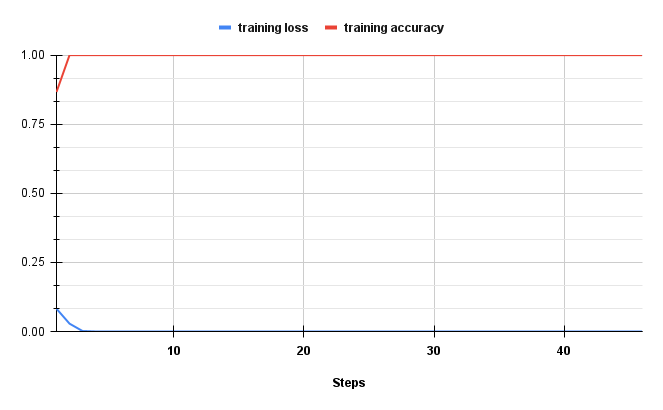
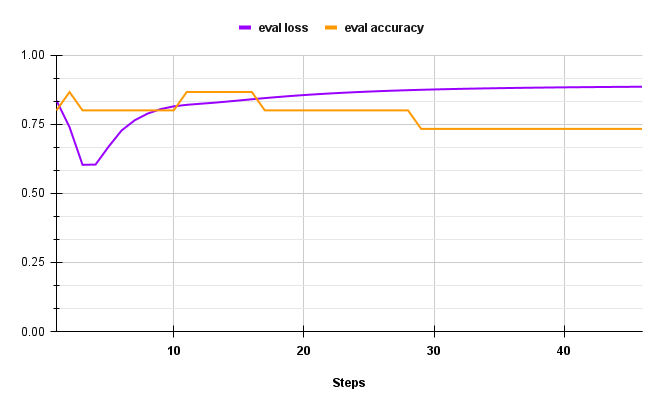
If the implementation is correct we expect to overfit the training batch in a few gradient updates: resulting in 0 training loss and 100 % training accuracy. Similarly, as the model keep overfitting a single training batch we expect the validation performances to degrade progressively. Figure 3 displays a good example of how the metrics should look at this stage.