Efficient and Scalable Machine Learning Pipelines
Jobs related to machine learning usually require managing massive datasets. A well-established rule of thumb that applies to most machine learning projects is that the larger and cleaner the dataset, the better the performance. Thus, the problem of preprocessing large amounts of data and efficiently feeding the produced dataset into the training pipeline emerges. While developing fancy models is a fun task for which limitless resources are available on the web, the ML community needs to cover better the topic of streamlining data preprocessing and ingestion pipelines. Backed by the fast iteration philosophy, this document aims to find the most efficient training process to minimise the cost of experimentation as more experiment results in better performance: as Elon Musk says, “high production rate solve many ills”.
To be as general as possible, this article follow the work done by [1] and will focus on finetuning a CLIP-like model on the farfetch dataset. This task’s choice enables us to preprocess a large number of images as well as text, which are the most common data-type currently used in machine learning.
Data Preprocessing
It is not a secret that the fuel of machine learning applications is data. For example, online advertising leverage behavioural data to personalise the displayed products, translation services leverage parallel documents, and research engine use users’ feedback to learn better query-document rankings. However, generating these datasets from the raw events is a challenging task. It is common knowledge that the larger the company, the messier the data; thus, carefully crafted transformation jobs are needed. Data preprocessing is the tedious step of collecting and integrating events from raw data sources and producing a well-formatted dataset that a training script can consume. As such, it is usually divided into two stages:
- Data engineering is the process of combining different data sources into a prepared dataset. During this process, we want to ensure that data sources are appropriately integrated and aggregated to the right granularity, possible errors are carefully handled, noise examples are removed, and the resulting dataset conforms to a well-defined schema.
- Feature engineering aims at converting all the columns of the generated dataset to the appropriate numerical format needed by the model. As such, this process is sometimes postponed to the data loading and augmentation process.
Nowadays, there is a multitude of libraries that can be used for data preprocessing. Apache Spark appears to be the best tool for data preprocessing jobs. It provides a Pandas-like interface; it is distributed so it can scale vertically and horizontally, integrated with the most common cloud environments, and supports batch and streaming data sources. While there a multiple approaches to speed up a preprocessing job, this article only focuses on comparing the different runtime engines supported by Spark:
- base engine designed to run on CPU clusters used as the baseline,
- photon engigne: engine: a C++ implementation of Spark that leverages vectorization operation to reduce the computation time,
- rapids engine: an emerging GPU-based environment provided by NVIDIA.
To compare the different engines, the text preprocessing task is used for benchmarking. As above mentioned, the dataset is the farfetch dataset that contains about 400K products, but about 300K are used for this test due to missing meaningful descriptions. Text preprocessing aims to clean, tokenize, pad and add special tokens to each product description. For consistency, we adopted the same tokenizer used in the original CLIP implementation. However, a pyspark UDF is used to apply the preprocessing to the original dataframe:
def encode(value):
# Petastorm specific enconding function for numpy array datatype.
# Read following section for a better explanation.
memfile = io.BytesIO()
np.save(memfile, value)
return bytearray(memfile.getvalue())
def get_preprocess_data_fn(
vocab_path: str
) -> Callable[[Iterator[pd.DataFrame]], Iterator[pd.DataFrame]]:
tokenizer = SimpleTokenizer(
vocab_path,
dtype=int,
)
def preprocess_data(
dataframe_batch_iterator: Iterator[pd.DataFrame]
) -> Iterator[pd.DataFrame]:
"""
UDF function to tokenize the items descriptions. Resulting
numpy array is encoded according to petestorm configuration.
"""
for dataframe_batch in dataframe_batch_iterator:
product_ids = []
descriptions_ids = []
for row in dataframe_batch.itertuples():
product_ids.append(int(row.product_id))
# tokenize description
description_ids = tokenizer(row.description)
# description_ids = description_ids.astype(np.int64)
# enconde numpy array as byte-array
descriptions_ids.append(encode(description_ids))
yield pd.DataFrame({
"product_id": product_ids,
"description_ids": descriptions_ids,
})
return preprocess_data
def main():
...
preprocess_data_fn = get_preprocess_data_fn(
path=vocab_path
)
# generate text encoding and image preprocessing
farfetch_description = farfetch_description.mapInPandas(
preprocess_data_fn,
StructType([
StructField("product_id", IntegerType()),
StructField("description_ids", BinaryType()),
])
)
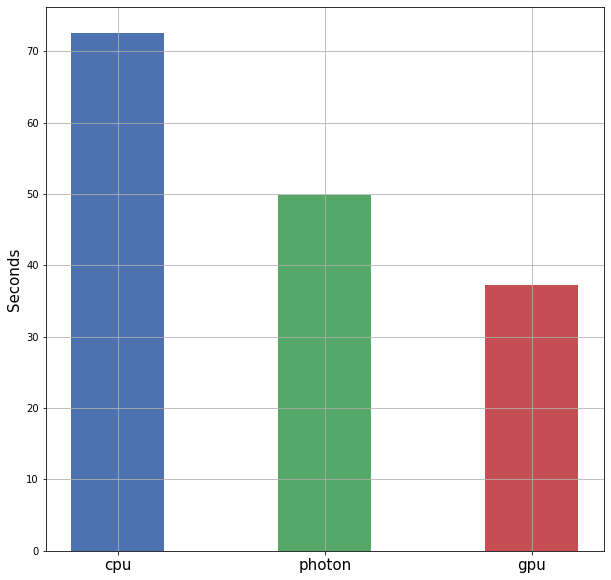
...Cluster configuration and experiment results are reported in Table 1 and Figure 1.
| CPU | Memory | GPU | Num Workers | Price (DBU/h) |
|---|---|---|---|---|
| 16 | 64 GB | 0 | 8 | 13.7 |
| Photon-accelerated | 16 | 64 GB | 0 | 8 |
| GPU-accelerated | 16 | 64 GB | NVIDIA T4 | 8 |
The experiment result shows that a reduction of 31.5 to 49% in processing time achievable just by adopting an accelerated engine. Rapids is the most promising option as it provides a 2x speedup at a competitive price w.r.t. the CPU baseline. However, not that in this test, the dataset size is small compared to the available cluster memory, and special care is usually required when working with GPUs as it is pretty common to get out-of-bound memory errors.
Data Ingestion
Data ingestion is another crucial component for any successful ML project. Too little credit has been given to the developers of Tensorflow Dataset and PyTorch DataLoaders as they provide common APIs for loading and manipulating the created datasets. However, these data-loaders utilities are limited when it comes to processing large datasets that do not fit the memory and that need to operate in a distributed environment. On the one hand, Tensorflow Dataset is extremely efficient when working with TFRecords, but does not support parquet data format and requires a significant amount of boilerplate code to be parsed. On the other hand, PyTorch Dataloaders only focuses on sampling and batching the data, leaving the scope of loading the dataset into the memory for rapid access indexed access to the user.
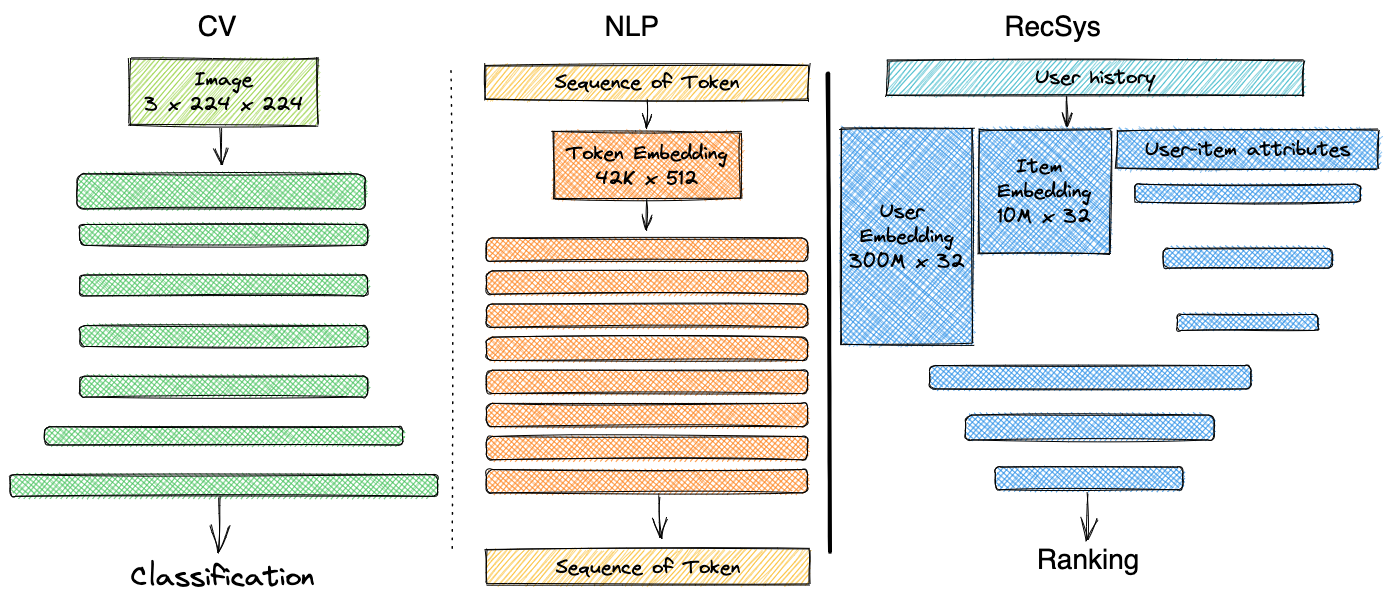
Due to these limitations, multiple third-party solutions arose. As shown in Figure 2 in machine learning there are two main type of datasets: - datasets composed by raw complex data formats such as images, texts or audios are common in deep learning; - tabular dataset are composed by multiple columns of scalar values representing handcrafted features are usually used in reccomandation applications. As this two datatypes present different challences, distinct benchmarks are conducted to understand which are the best practices to follow in differnet scenarios.
Complex Raw Datasets
These types of datasets are composed of a mixture of texts, images and audio in the form of large multi-dimensional arrays. The large input space requires deep models to learn good embeddings of the data. Thus, it is assumed that the forward and backward passes of the model is the main bottelneck of the training phase due to the model’s complexity. Instead, the data loading process is assumed to be comparatively less expensive.
Based on these assumptions, a common pattern emerged across the dataloaders solutions: spawning thread-based or process-based workers to ingest the data while the GPUs are used for training. Among the others, Petastorm, a general-purpose solution provided by Uber that easily integrates with Databricks, follows exactly this pattern. At the core of Petastorm, there is the Codecs concept, an API that specifies methods to encode and decode custom datatypes. For example, numpy arrays and images, two types not supported by Spark, are encoded by Petastorm into a Spark DataFrames as BinaryType and decoded at training time. As above mentioned, when a new column containing a non-native datatype is added to the DataFrame, the encode function is applied to every row.
def encode(value)
memfile = BytesIO()
np.save(memfile, value)
return bytearray(memfile.getvalue())Similarly, once the dataset is stored on any distributed file system, the Petastorm Reader decodes each row of the dataset while feeding the data into the training pipeline.
def decode(value)
memfile = BytesIO(value)
return np.load(memfile)Yet, performing random access of distributed datasets containing large arrays is costly due to the multiple I/O operations involved. Thus, an evaluation of Petastorm dataloaders, on the dataset previously prepared is reported. The dataset consists of about 300K image/text pairs. Images are represented as 3 x 224 x 224 arrays, while text by a list of 77 elements. Each batch is composed of 64 examples. The objective is to find the best worker-type and number of worker combinations possible. Thus, a grid search is reported in [fig-dataloader-cn-nlp-bnc], where thread-based and process-based workers are compared with a setting that uses 5, 10 and 20 workers.
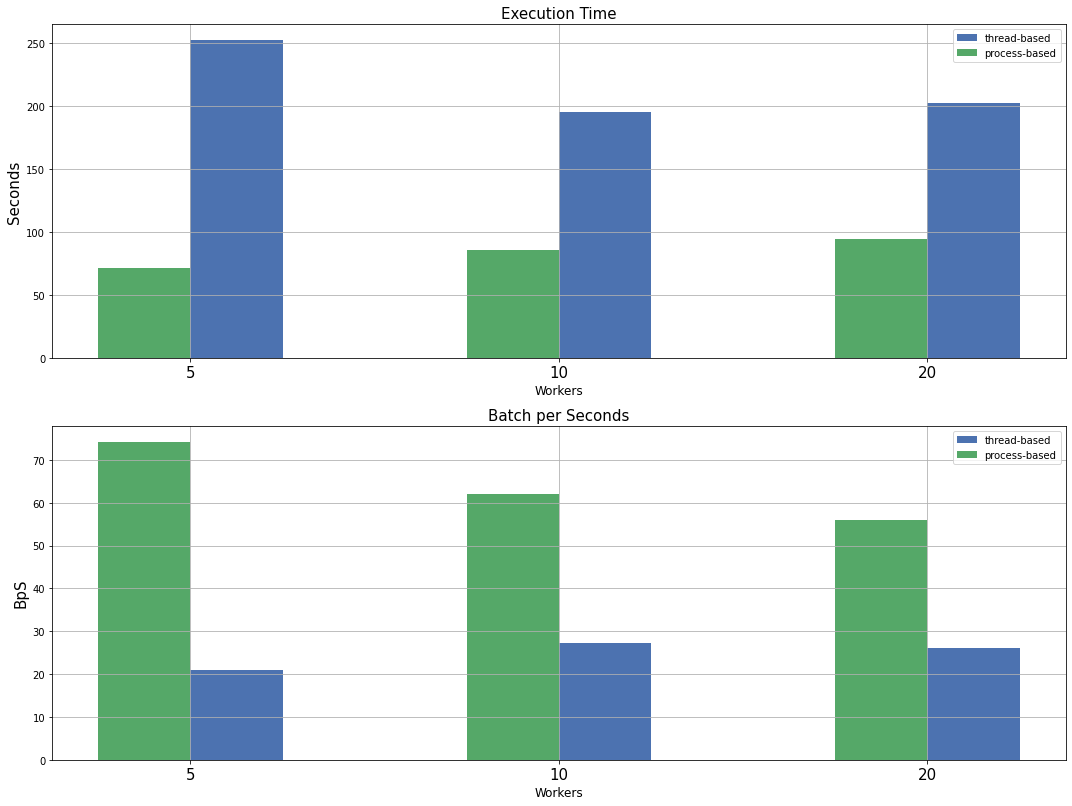
The results show that a setting with 5 processes is the fastest as it can process 74 batches per second (BpS), which is a 172 % improvement over the default configuration (threaded with 10 workers). 74 batches per second might seem like a bad result, but the computational cost of a deep model would likely be an order of magnitude larger, even if working in a data-parallel setting. Thus, most of the research focuses on speeding up the model computational time with strategies like model pruning, mixed-precision, ecc.
Tabular Datasets
Tabular datasets are commonly found in recommendation systems (RecSys) applications where the objective is to score (user, item) or (query, document) pairs. RecSys have key differences w.r.t. other deep learning applications:
- many recommendation applications need to perform in a real-time environment; thus the models need to satisfy tight latency constraints;
- the datasets are usually large since the collection of (weakly) labelled examples is inexpensive;
- the inputs are composed of a large set of handcrafted features.
In the RecSys settings, efficient data-loading pipelines are an extremely important component of the training phase as the computational cost of the model is relatively small w.r.t. the loading operations. Note that, this is the exact opposite of the traditional deep learning environment, thus the multi-worker solution might perform poorly. To this end, custom-designed solutions for tabular datasets such as NVIDIA Merlin emerged. Merlin is a complete toolkit for hardware-accelerated RecSys systems built on top of Dask, cuDF and Rapids. Merlin dataloader is a package specifcally built for the RecSys usecase; it leverages cuDF to efficiently load data into the GPUs and DLPack to transfer the data to the appropriate backend framework (usually Tensorflow, PyTorch or JAX).
To evaluate the importance of having efficient data-loading solutions in this setting, a benchmark of Petastorm, Tensorflow Datasets with TFRecords and Merlin dataloader is conducted. The dataset used for the experiment is composed of ~8 M examples. Each row is composed of 100 columns containing only scalar values. A batch is 64 examples is loaded at each step.
The following setups are used to fine-tune each framework:
- Petastorm uses 5 or 10 workers in a thread or process-based solutions;
- Tensorflow uses 5 or 10 workers for reading and parsing the TFRecords;
- Merlin uses the default configuration.
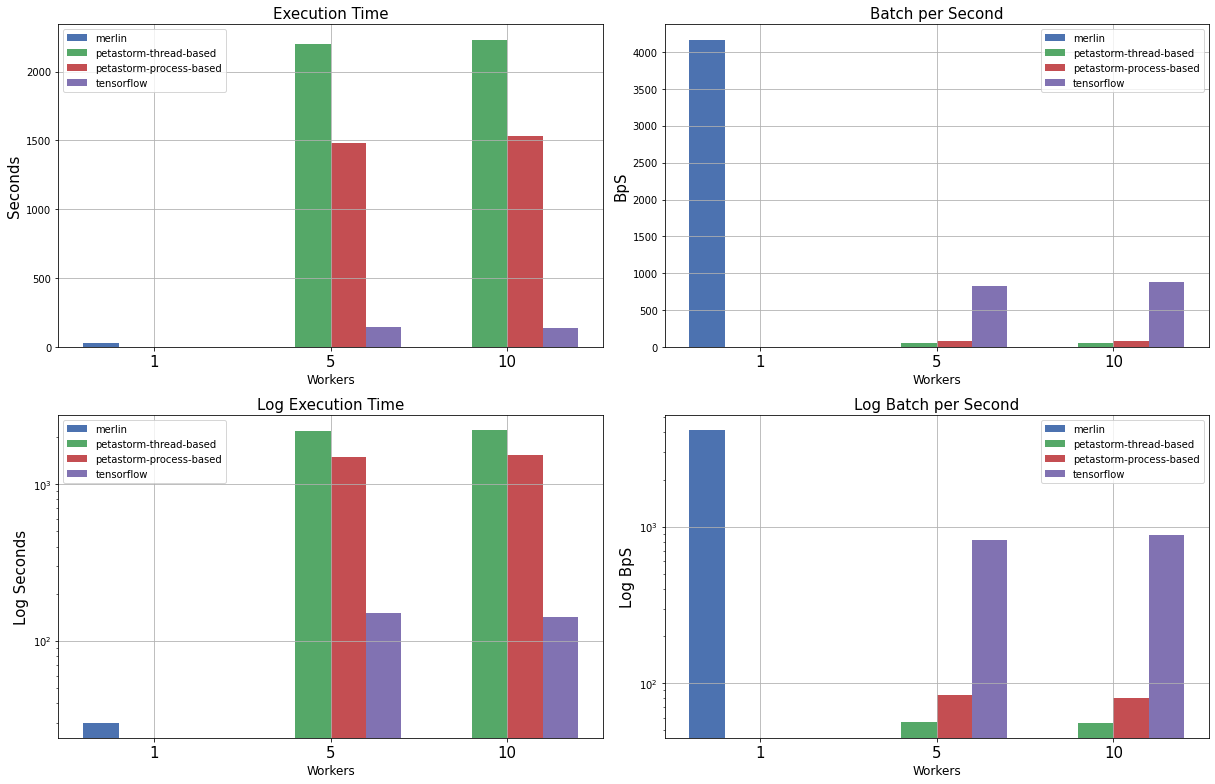
Figure 4 highlights how a general-purpose solution like Petastorm does not fit the RecSys settings as it is more than 1000x slower than Merlin. Tensorflow Datasets are showing decent performances, but handling TFRecords is challenging as they consume a large amount of disk space and need to know the dataset schema at parsing time. Without many surprises, Merlin demonstrates astonishing performances being more than 4000 batches per second and it is 10 times faster than Tensorflow while being almost a plug-and-play solution if the datasets are stored in a parquet format. Unfortunately, Merlin does not support any other datatype than numerical values; thus datasets containing strings and multi-dimensional arrays are not supported.